Hive Introduction-2
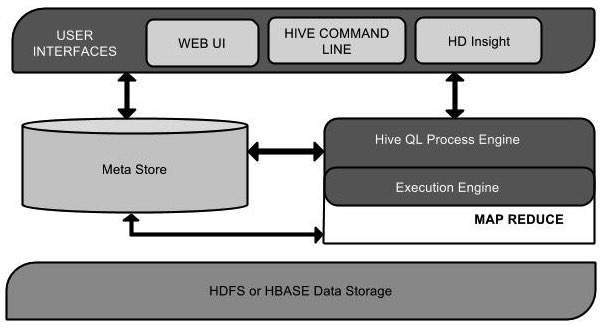
The main components of Hive are:
- Metastore: It stores all the metadata of Hive. It stores data of data stored in database, tables, columns, etc.
- Driver: It includes compiler, optimizer and executor used to break down the Hive query language statements.
- Query compiler: It compiles HiveQL into graph of map reduce tasks.
- Execution engine: It executes the tasks produces by compiler.
- Thrift server: It provides an interface to connect to other applications like MySQL, Oracle, Excel, etc. through JDBC/ODBC drivers.
- Command line interface: It is also called Hive shell. It is used for working with data either interactively or batch data processing.
- Web Interface: It is a visual structure on Hive used for interaction with data.
Data Storage in Hive:
Hive has different forms of storage options and they include:
- Metastore: Metastore keeps track of all the metadata of database, tables, columns, datatypes etc. in Hive. It also keeps track of HDFS mapping.
- Tables: There can be 2 types of tables in Hive. First, normal tables like any other table in database. Second, external tables which are like normal tables except for the deletion part. HDFS mappings are used to create external tables which are pointers to table in HDFS. The difference between the two types of tables is that when the external table is deleted its data is not deleted. Its data is stored in the HDFS whereas in case of normal table the data also gets deleted on deleting the table.
- Partitions: Partition is slicing of tables that are stored in different subdirectory within a table’s directory. It enhances query performance especially in case of select statements with “WHERE” clause.
- Buckets: Buckets are hashed partitions and they speed up joins and sampling of data.
Hive vs. RDBMS (Relational database)
Hive and RDBMS are very similar but they have different applications and different schemas that they are based on.
- RDBMS are built for OLTP (Online transaction processing) that is real time reads and writes in database. They also perform little part of OLAP (online analytical processing).
- Hive is built for OLAP that is real time reporting of data. Hive does not support inserting into an existing table or updating table data like RDBMS which is an important part of OLTP process. All data is either inserted in new table or overwritten in existing table.
- RDBMS is based on write schema that means when data is entered in the table it is checked against the schema of table to ensure that it meets the requirements. Thus loading data in RDBMS is slower but reading is very fast.
- Hive is based on read schema that means data is not checked when it is loaded so data loading is fast but reading is slower.
Hive Query Language (HQL)
HQL is very similar to traditional database. It stores data in tables, where each table consists of columns and each column consists of specific number of rows. Each column has its own data type. Hive supports primitive as well as complex data types. Primitive types like Integer, Bigint, Smallint, Tinyint, Float, Double Boolean, String, and Binary are supported. Complex types include Associative array: map , Structs: struct , and Lists: list .
Data Definition statements (DDL) like create table, alter table, drop table are supported. All these DDL statements can be used on Database, tables, partitions, views, functions, Index, etc. Data Manipulation statements (DML) like load, insert, select and explain are supported. Load is used for taking data from HDFS and moving it into Hive. Insert is used for moving data from one Hive table to another. Select is used for querying data. Explain gives insights into structure of data.